Introduction to Nomad Cluster Operation

 Server v2.x Server Admin
Server v2.x Server Admin | CircleCI Server version 2.x is no longer a supported release. Please consult your account team for help in upgrading to a supported release. |
CircleCI uses Nomad as the primary job scheduler. This chapter provides a basic introduction to Nomad for understanding how to operate the Nomad Cluster in your CircleCI installation.
Basic Terminology and Architecture
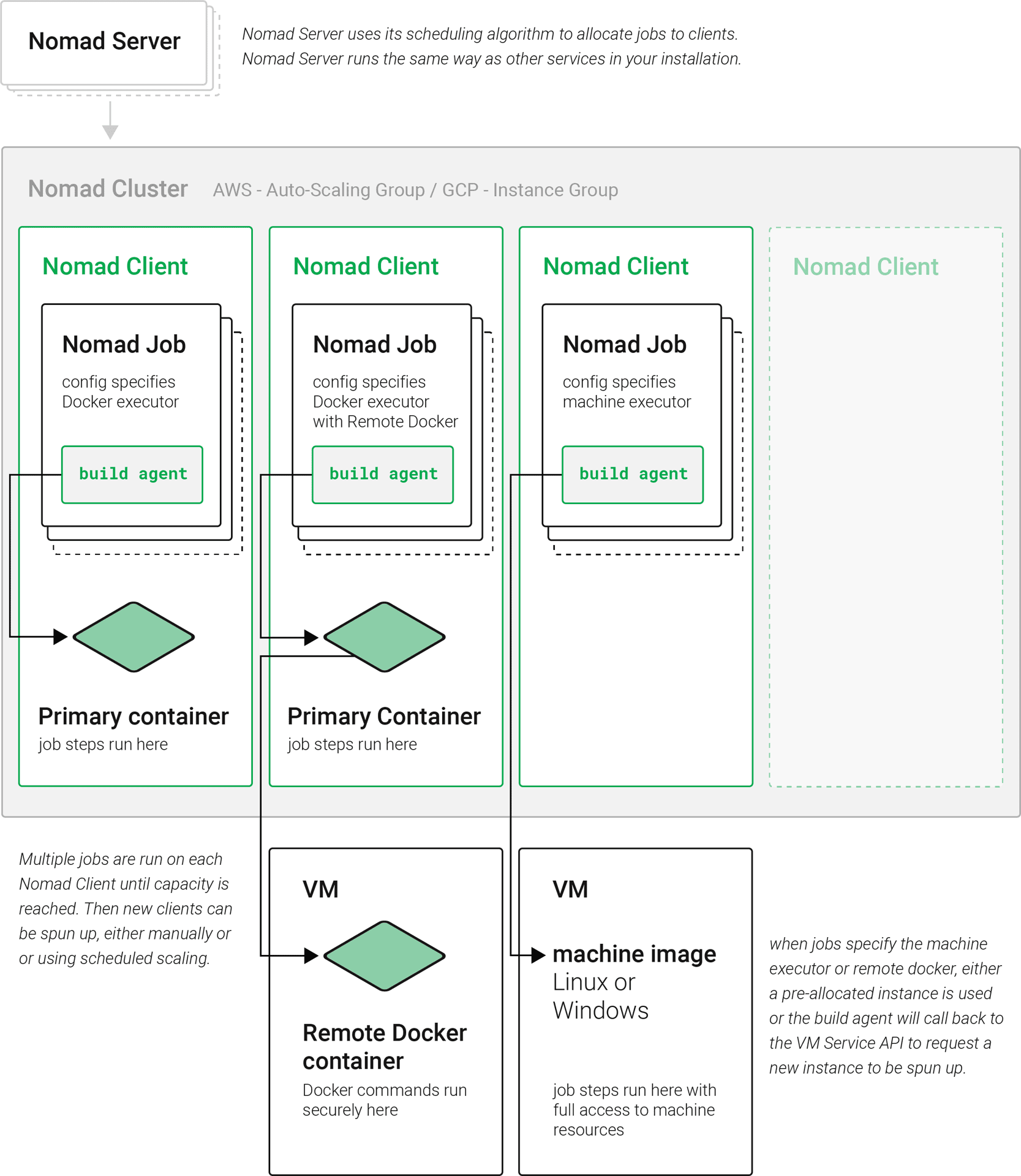
-
Nomad Server: Nomad servers are the brains of the cluster; they receive and allocate jobs to Nomad clients. In CircleCI, a Nomad server runs on your Services machine as a Docker Container.
-
Nomad Client: Nomad clients execute the jobs they are allocated by Nomad servers. Usually a Nomad client runs on a dedicated machine (often a VM) in order to fully take the advantage of machine power. You can have multiple Nomad clients to form a cluster and the Nomad server allocates jobs to the cluster with its scheduling algorithm.
-
Nomad Jobs: A Nomad job is a specification, provided by a user, that declares a workload for Nomad. A Nomad job corresponds to an execution of a CircleCI job. If the job uses parallelism, say 10 parallelism, then Nomad will run 10 jobs.
-
Build Agent: Build Agent is a Go program written by CircleCI that executes steps in a job and reports the results. Build Agent is executed as the main process inside a Nomad Job.
Basic Operations
The following section is a basic guide to operating a Nomad cluster in your installation.
The nomad CLI is installed in the Service instance. It is pre-configured to talk to the Nomad cluster, so it is possible to use the nomad command to run the following commands in this section.
Checking the Jobs Status
The get a list of statuses for all jobs in your cluster, run:
nomad statusThe Status is the most important field in the output, with the following status type definitions:
-
running: Nomad has started executing the job. This typically means your job in CircleCI is started. -
pending: There are not enough resources available to execute the job inside the cluster. -
dead: Nomad has finished executing the job. The status becomesdeadregardless of whether the corresponding CircleCI job/build succeeds or fails.
Checking the Cluster Status
To get a list of your Nomad clients, run:
nomad node-status nomad node-status reports both Nomad clients that are currently serving (status active) and Nomad clients that were taken out of the cluster (status down). Therefore, you need to count the number of active Nomad clients to know the current capacity of your cluster. |
To get more information about a specific client, run the following from that client:
nomad node-status -selfThis will give information such as how many jobs are running on the client and the resource utilization of the client.
Checking Logs
As noted in the Nomad Jobs section above, a Nomad Job corresponds to an execution of a CircleCI job. Therefore, Nomad Job logs can sometimes help to understand the status of a CircleCI job if there is a problem. To get logs for a specific job, run:
nomad logs -job -stderr <nomad-job-id> Be sure to specify the -stderr flag as this is where most Build Agent logs appear. |
While the nomad logs -job command is useful, the command is not always accurate because the -job flag uses a random allocation of the specified job. The term allocation is a smaller unit in Nomad Job, which is out of scope for this document. To learn more, please see the official document.
Complete the following steps to get logs from the allocation of the specified job:
-
Get the job ID with
nomad statuscommand. -
Get the allocation ID of the job with
nomad status <job-id>command. -
Get the logs from the allocation with
nomad logs -stderr <allocation-id>
Scaling the Cluster
By default, your Nomad Client is set up within an Auto Scaling Group (ASG) within AWS. To view settings:
-
Go to your EC2 Dashboard and select Auto Scaling Groups from the left hand menu
-
Select your Nomad Client
-
Select Actions > Edit to set Desired/Minimum/Maximum counts. This defines the number of Nomad Clients to spin up and keep available. Use the Scaling Policy tab to scale up your group automatically at your busiest times, see below for best practices for defining scaling policies. Use nomad job metrics to assist in defining your scaling policies.
Auto Scaling Policy Best Practices
There is a blog post series wherein CircleCI engineering spent time running simulations of cost savings for the purpose of developing a general set of best practices for Auto Scaling. Consider the following best practices when setting up AWS Auto Scaling:
-
In general, size your cluster large enough to avoid queueing builds. That is, less than one second of queuing for most workloads and less than 10 seconds for workloads run on expensive hardware or at highest parallellism. Sizing to reduce queuing to zero is best practice because of the high cost of developer time. It is difficult to create a model in which developer time is cheap enough for under-provisioning to be cost-effective.
-
Create an Auto Scaling Group with a Step Scaling policy that scales up during the normal working hours of the majority of developers and scales back down at night. Scaling up during the weekday normal working hours and back down at night is the best practice to keep queue times down during peak development, without over provisioning at night when traffic is low. Looking at millions of builds over time, a bell curve during normal working hour emerges for most data sets.
This is in contrast to auto scaling throughout the day based on traffic fluctuations, because modelling revealed that boot times are actually too long to prevent queuing in real time. Use Amazon’s Step Policy instructions to set this up along with Cloudwatch Alarms.
Shutting Down a Nomad Client
When you want to shutdown a Nomad client, you must first set the client to drain mode. In drain mode, the client will finish any jobs that have already been allocated but will not be allocated any new jobs.
-
To drain a client, log in to the client and set the client to drain mode with
node-draincommand as follows:nomad node-drain -self -enable -
Then, make sure the client is in drain mode using the
node-statuscommand:nomad node-status -self
Alternatively, you can drain a remote node with the following command, substituting the node ID:
nomad node-drain -enable -yes <node-id>Scaling Down the Client Cluster
To set up a mechanism for clients to shutdown, first enter drain mode, then wait for all jobs to be finished before terminating the client. You can also configure an ASG Lifecycle Hook that triggers a script for scaling down instances.
The script should use the commands in the section above to do the following:
-
Put the instance in drain mode
-
Monitor running jobs on the instance and wait for them to finish
-
Terminate the instance
Help make this document better
This guide, as well as the rest of our docs, are open source and available on GitHub. We welcome your contributions.
- Suggest an edit to this page (please read the contributing guide first).
- To report a problem in the documentation, or to submit feedback and comments, please open an issue on GitHub.
- CircleCI is always seeking ways to improve your experience with our platform. If you would like to share feedback, please join our research community.
Need support?
Our support engineers are available to help with service issues, billing, or account related questions, and can help troubleshoot build configurations. Contact our support engineers by opening a ticket.
You can also visit our support site to find support articles, community forums, and training resources.

CircleCI Documentation by CircleCI is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

